
Open Legal Data: Das Fundament des Rechtsstaates
Nur sehr wenige Gerichte in Deutschland veröffentlichen systematisch ihre Entscheidungen - ein großes Problem im Hinblick auf den verfassungsrechtlichen Grundsatz der Gerichtsöffentlichkeit und das Rechtsstaatsprinzip. Der Artikel skizziert Probleme die durch die fehlende Verfügbarkeit freier juristischer Daten entstehen, erläutert Anwendungsbeispiele mit Praxisbezug und zeigt Wege aus der Misere auf.
Das Ideal von Open Legal Data - die freie Verfügbarkeit juristischer Daten - ist keine Erfindung des Internets, sondern eine zentrale demokratische Errungenschaft und das Fundament des modernen Rechtsstaats. So schreibt § 5 I UrhG die Urheberrechtsfreiheit für “Gesetze, Verordnungen, amtliche Erlasse und Bekanntmachungen sowie Entscheidungen und amtlich verfaßte Leitsätze zu Entscheidungen” vor. Nach § 5 II UrhG gilt das gleiche für “andere amtliche Werke, die im amtlichen Interesse zur allgemeinen Kenntnisnahme veröffentlicht worden sind”. Willkür und Geheimjustiz lassen sich nur verhindern wenn Bürger:innen eine realistische Chance haben das jeweils gültige Recht zu erkennen und ihr Verhalten danach auszurichten. Das bedeutet konkret die Möglichkeit der Kenntnisnahme nicht nur von Gesetzen und Verordnungen, sondern auch von der in der juristischen Praxis überragend wichtigen Rechtsprechung und anderen juristischen Dokumenten, die staatliche Machtausübung legitimieren und umsetzen.
So schreibt das Bundesverfassungsgericht in seinem Beschluss vom 14. September 2015 - 1 BvR 857/15, dass “der Grundsatz der Gerichtsöffentlichkeit selbst Bestandteil des Rechtsstaatsprinzips ist (vgl. BVerfGE 103, 44 <63>) und eine Rechtspflicht zur Publikation veröffentlichungswürdiger Gerichtsentscheidungen allgemein anerkannt ist (vgl. BVerwGE 104, 105 <108 f.> m.w.N.)”. Dem Bundesverwaltungsgericht zufolge “handelt sich um eine verfassungsunmittelbare Aufgabe der rechtsprechenden Gewalt und damit eines jeden Gerichts. Zu veröffentlichen sind alle Entscheidungen, an deren Veröffentlichung die Öffentlichkeit ein Interesse hat oder haben kann” (BVerwG, Urteil vom 26.02.1997 - 6 C 3.96). Demnach reicht schon das potentielle Interesse der Öffentlichkeit aus um eine Pflicht zur Veröffentlichung zu begründen.
Soweit der Traum des Rechtsstaates. In der Realität werden die allermeisten gerichtlichen Entscheidungen - besonders die der Instanzgerichte - nicht veröffentlicht, geschweige denn in einem maschinenlesbaren Format. Die Bundesgerichte bieten ihre Entscheidungen ungefähr ab dem Entscheidungsjahr 2000 vollständig zum Download an (BVerfG ab 1998, BSG ab 2018). Entscheidungen der Bundesgerichte in maschinenlesbaren Formaten wie XML sind allerdings erst ab dem Entscheidungsjahr 2010 verfügbar (www.rechtsprechung-im-internet.de). Ein Beispiel: Abbildung 1 zeigt die Anzahl der auf der amtlichen Webseite des Bundesverfassungsgerichts veröffentlichten Entscheidungen abhängig vom Entscheidungsjahr (Quelle: https://doi.org/10.5281/zenodo.4308215).
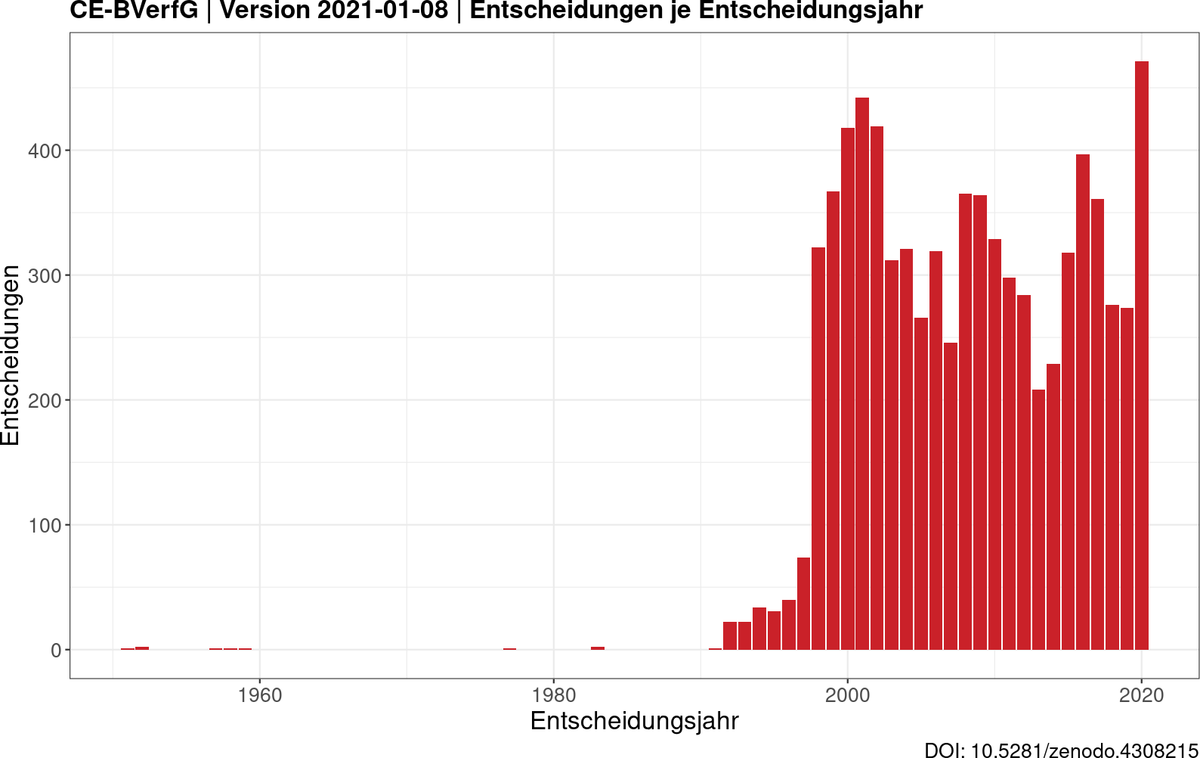
Bei den Gerichten der Länder ist die Situation besonders desolat. Ein Beispiel: Bayern stellt die Entscheidungen seiner Gerichte erst ab dem Entscheidungsjahr 2016, nicht maschinenlesbar und nicht einmal urheberrechtsfrei zur Verfügung (der Verlag C.H. Beck scheint Rechte an ihnen zu halten). Beschreibenderweise unter einer URL, die keinen Hinweis darauf bietet, dass dort auch Rechtsprechung angeboten wird: https://www.gesetze-bayern.de/.
Für Gesetze und Verordnungen stellt der Bund (www.gesetze-im-internet.de) jeweils nur die aktuellste Fassung zur Verfügung, eine missliche Lage bei länger andauernden Verfahren, die auf einer älteren Rechtslage beruhen. Selbst das Bundesgesetzblatt wird nur über die kommerzielle Bundesanzeiger Verlag GmbH vertrieben, der kostenlose Bürgerzugang ist funktional wertlos.
Die Konsequenz ist eine faktische Teilprivatisierung des Rechtsstaats. Juristische Arbeit im Jahr 2021 ist kaum denkbar ohne die Zuhilfenahme kommerzieller Datenbanken. Streng genommen besteht keine berufsrechtliche Pflicht zur Nutzung, aber für Anwält:innen die nur die Rechtsprechung ab 2000 berücksichtigen ist der Haftungsfall fast vorprogrammiert. Ob Richter:innen ihren verfassungsrechtlichen Pflichten ohne solche Datenbanken nachkommen können ist ebenfalls zweifelhaft. Besonders pikant: die juris GmbH - einer der führenden kommerziellen Datenbank-Anbieter - steht zu 50,01% in Bundeseigentum. Der Zugang zum Rechtsstaat wird in dieser Form nicht als öffentliche Aufgabe verstanden, sondern als Produktion eines skalierbar handelbaren Wirtschaftsguts von erheblichem Marktwert.
Anwendungen
Allein die rechtsstaatliche Bedeutung des öffentlichen Zugangs zu juristischen Dokumenten der drei Gewalten wäre schon ein überzeugender Grund für Open Legal Data, aber das volle Potential freier Daten entfaltet sich erst im Zusammenwirken mit den modernsten digitalen Technologien. Klassische juristische Datenbanken sind weithin bekannt und aus der täglichen Arbeit nicht hinwegzudenken. Freie Alternativen wie OpenJur (https://openjur.de/), OpenLegalData.io (http://openlegaldata.io/) oder ein neuartiges staatliches Rechtsinformationsportal könnten sich mit ausreichend Daten zu ernsthaften Konkurrenten kommerzieller Anbieter entwickeln oder - wie Wikipedia den Brockhaus - vollständig mit einem starken offenen Angebot verdrängen. Kommerzielle Anbieter setzen zur Kundenbindung derzeit vor allem auf ihren Datenreichtum und nicht auf eine besonders innovative Bereitstellung rechtlicher Informationen.
Spannende und neuartige Konzepte für die juristische Informationsvermittlung werden aktuell in vielen Forschungsbereichen entwickelt. Es muss auch nicht immer gleich künstliche Intelligenz sein (der Begriff verspricht ohnehin mehr, als er halten kann), wie ich aus eigener Forschung berichten kann.
Abbildung 2 zeigt eine von mir mit der statistischen Programmiersprache R erzeugte Zusammenstellung der BVerfGE ab 1998, angereichert mit Entscheidungsnamen, Fundstellen und vielen weiteren menschen- und maschinenlesbaren Informationen. Der Datensatz ist open access und urheberrechtsfrei. Neben dem maschinenlesbaren CSV-Format (ein einfaches Tabellen-Format) ist er auch als bequeme PDF-Sammlung für die traditionelle juristische Arbeit erhältlich und mit einem Klick hier downloadbar: https://doi.org/10.5281/zenodo.3831111
Abbildung 3 ist eine (technisch wenig anspruchsvolle) Untersuchung der Volltexte aller Entscheidungen des Bundesverfassungsgerichts seit 1998 auf die Schlagworte “Corona”, “COVID” und “SARS-CoV”. Jede Zeile ist eine Entscheidung (jeweils in der rechten Spalte mit Datum, Aktenzeichen usw.) und jeder vertikale Strich ein Treffer. Alle Dokumente sind jeweils auf eine Länge von 1.0 normalisiert, um die Interpretiarbarkeit zu verbessern. Ein Strich bei 0.50 würde einem Treffer exakt in der Mitte einer Entscheidung entsprechen. Soweit so wissenschaftlich.
Richtig praxistauglich wird diese Analyse dadurch, dass sich jedes dieser Dokumente vollautomatisiert aus dem gesamten Datensatz herausfiltern und in eine neue Sammlung überführen lässt. Das Ergebnis: die gesamte Corona-Rechtsprechung des BVerfG aus dem Jahr 2020 in einer schnell erfassbaren Visualisierung und in einer bequemen PDF-Sammlung zum genauen Nachlesen, hier zum Download (open access und urheberrechtsfrei): https://doi.org/10.5281/zenodo.4459405
Kommentarliteratur behauptet oft die systematische Untersuchung eines Rechtsgebietes, mit Open Legal Data und statistischen Methoden wird sie Wahrheit. Der Charakter der deutschen Rechtswissenschaft als Schlagwort-Wissenschaft erleichtert dieses Vorgehen erheblich.
Diese beiden Beispiele kratzen nur an der Oberfläche von dem, was mit modernen statistischen Methoden der Textverarbeitung (“Natural Language Processing”) möglich ist. Es lässt sich zum Beispiel eine Suche implementieren, bei der ein Urteil oder ein Schriftsatz hochgeladen wird und ein Algorithmus vollautomatisch ähnliche und relevante Dokumente vorschlägt. Die Erforschung von juristischen Netzwerken auf Basis von Zitationsanalysen wird insbesondere von der quantlaw-Gruppe um Dr. Corinna Coupette in Hamburg vorangetrieben (https://www.quantitative-rechtswissenschaft.de/).
Die Zukunft der automatisierten juristischen Textverarbeitung liegt aber vermutlich in komplexen machine learning-Modellen wie BERT oder GPT-3 (oft als “künstliche Intelligenz” bezeichnet - streng genommen ist es nichts dergleichen). GPT-3 ist ein Transformer-Modell auf Basis von neuronalen Netzwerken mit 175 Milliarden Parametern und kann Anfragen in natürlicher Sprache entgegennehmen und komplexe Antworten in natürlicher Sprache ausgeben. Solche Modelle sind nur auf Basis gigantischer Textsammlungen realisierbar. Auf den juristischen Kontext übertragen ließen sich zum Beispiel Urteile zusammenfassen, in Alltagssprache oder einfache Sprache übersetzen, komplexe juristische Recherche-Anfragen stellen oder Vorlagen für Urteile generieren. Das oft beschworene Gespenst des Robo-Richters wird dadurch nicht Realität, im Gegenteil: Gerichtsverfahren, besonders in sensiblen Bereichen wie dem Strafrecht oder dem Familienrecht, kommen nicht ohne menschliche Interaktion aus. Keine Maschine kann den menschlichen Kontakt mit den Parteien oder die freie Beweiswürdigung in neuartigen Situationen ersetzen. Richter:innen können aber auf eine deutliche Entlastung von zeitraubenden Routine-Tätigkeiten hoffen.

Umsetzung
Wie lassen sich Gerichte und Verwaltungen also digitalisieren und Prozesse für Open Legal Data öffnen? Natürlich könnte man klassische Papier-Arbeitsergebnisse digitalisieren und maschinenlesbar aufbereiten (typischerweise durch die Wissenschaft), aber die besten Daten stammen aus volldigitalisierten Arbeitsprozessen, die diese gezielt und datenschutzkonform maschinenlesbar freigeben. Die für die maschinenlesbare Bereitstellung von Entscheidungen und anderen juristischen Daten nötige flächendeckende Einführung von digitalen Prozessen ist allerdings eine Herkules-Aufgabe.
Typischerweise reagieren staatliche Stellen auf große Herausforderungen mit großen Ausschreibungen, auf die große Projekte folgen, die mit großen Problemen kämpfen und große Aufregung verursachen. Der neue Flughafen Berlin Brandenburg (BER) und Stuttgart 21 haben viele Kommentator:innen in Lohn und Brot gehalten. Aber auch im juristischen Bereich finden sich genug Beispiele für wenig glückliche IT-Großprojekte, beispielsweise das besondere elektronische Anwaltpostfach (beA). Ein Flughafen kann kaum anders entwickelt und gebaut werden denn als Großprojekt, bei IT-Projekten stehen aber auch andere Herangehensweisen zur Verfügung: Open Source und agile Entwicklung.
Agile Entwicklung ist im Grunde allen Jurist:innen schon aus dem Studium bekannt. Statt einen Problemkomplex schon beim ersten Versuch mit einer perfekten Lösung aus dem Weg zu schaffen werden bei der agilen Entwicklung in kurzen Zyklen funktionale Lösungen für dringende und/oder wichtige Probleme geschaffen, in der Praxis von Nutzer:innen getestet und basierend auf dem Feedback der Nutzer:innen ständig überarbeitet. Das Prinzip ist kein anderes als das Schreiben von Dutzenden Probeklausuren vor dem Staatsexamen. Auch hier schreiben die Entwickler (= Prüflinge) in kurzer Zeit funktionale Lösungen für dringende und wichtige Probleme (= Schwertpunksetzung in der Klausur), erhalten Feedback von Nutzer:innen (= Korrektor:innen) und überarbeiten basierend auf dem Feedback ständig ihre Arbeitsprozesse um schließlich beim Release ihres Produktes (= Staatsexamen) den Anforderungen der Realität gewachsen zu sein. Die meisten Jurist:innen werden ihre Staatsexamina deshalb hoch-agil entwickelt haben! Open Source ist die ideale Ergänzung zur agilen Entwicklung. Dabei findet der ganze agile Prozess in der Öffentlichkeit statt und kann durch die ganze Gesellschaft unterstützt werden.
Agile Ideen können auf einer Vielzahl von Wegen in Justiz und Verwaltung etabliert werden. Zwei Modelle möchte ich besonders hervorheben:
Ein besonders schönes Beispiel sind die Fellowships von Tech4Germany (https://tech.4germany.org/), einer Initiative unter der Schirmherrschaft des Bundeskanzleramts. Tech4Germany stellt Teams aus 4 externen Technologie-Experten (“Fellows”) und 2-3 Digital-Lots:innen aus Ministerien oder Behörden des Bundes zusammen. Diese bearbeiten in 12 Wochen drängende und wichtige Probleme der Bundesverwaltung und entwickeln direkt funktionale Prototypen bzw. Lösungen für diese. Im Jahr 2020 ist durch ein solches Projekt innerhalb von 12 Wochen die Alpha-Version für ein neues Rechtsinformationsportal des Bundes entstanden: https://tech.4germany.org/project/rechtsinformationsportal/
Eine weitere Möglichkeit wären prozentuale Zeit-Budgets zur Entlastung bestehender Mitarbeiter:innen, die es ihnen erlauben würden ohne konkrete Zielvorgaben Lösungen für Probleme zu entwickeln, die sie auf Basis ihrer eigenen Erfahrung im Beruf für dringend und/oder wichtig halten.
Google ist mit seiner “20%-time” berühmt geworden, aus der Produkte wie Gmail oder Google News hervorgegangen sein sollen. Große Anwaltskanzleien ermöglichen es aktuell immer häufiger ihren Anwälten 50% oder mehr ihrer Arbeitsleistung für Legal Tech-Projekte einzusetzen. An Gerichten finden sich Entlastungs-Modelle vor allem für die Arbeit als Pressesprecher:in. Warum nicht einfach Probleme der Digitalisierung durch ein 50%-Modell für eine kleinere Anzahl Personen oder ein 20%-Modell für eine größere Anzahl Personen angehen? Für konkrete IT-Vorhaben wird dieses Modell in Berlin bereits praktiziert - wenn auch nur spärlich. Gerade Richter:innen sind herausragend im selbstverantwortlichen Umgang mit ihrer Zeit und in der Lage komplexe Verfahren eigenständig zum Abschluss zu bringen. Ein Beispiel: Professor Jan F. Orth, Richter am Landgericht Köln, hat neben seiner regulären Tätigkeit bei Gericht die iOS App “Richter-Tools” entwickelt, die sich gerade im Beta-Stadium befindet: https://www.janforth.de/richter-tools/
Es wäre natürlich utopisch zu erwarten, dass 12-wöchige Fellowships oder kleine Gruppen von agil arbeitenden Richter:innen allein alle digitalen Probleme der Justiz lösen werden. Großprojekte wird es auch weiterhin brauchen und geben. Aber durch eine Kultur der agilen Entwicklung werden Probleme viel früher erkannt, es werden Ideen gesammelt und Lösungen im Kleinen entwickelt, sofort getestet und beibehalten oder verworfen. Selbst viele kleine Lösungen bringen in der Summe viele Vorteile. Auch können sie später als Grundlage für größere Projekte dienen, besonders wenn digital- und projekterfahrene Richter:innen für die Planung zur Verfügung stehen. Überraschend viele Software-Lösungen sind zudem skalierbar, d.h. wenn sie im Kleinen funktionieren, dann funktionieren sie oft auch (mit einigen Anpassungen) im Großen.
Schließlich ermöglichen Open Source und Open Legal Data die einfache, schnelle und transparente Kooperation zwischen Bundesländern, mit der Wissenschaft, der Zivilgesellschaft und der Öffentlichkeit. Der bundesdeutsche demokratische Föderalismus ist nichts anderes als der Protoyp des Open Source- und Open Data Gedankens. Bund und 16 Länder entwickeln gemeinsam oder unabhängig voneinander Lösungen für gesellschaftliche Probleme, Wissenschaft, Zivilgesellschaft und Öffentlichkeit diskutieren, verbessern, kritisieren und im Idealfall setzt sich die beste Lösung durch. Großartige Beispiele agilen zivilgesellschaftlichen Engagements für den Staat finden sich bei Code for Germany (https://codefor.de/) oder dem #WirVsVirus-Hackathon der Bundesregierung (https://wirvsvirus.org/). Brandneu ist die aktuell laufende Initiative “Update Deutschland” (https://updatedeutschland.org/) unter Schirmherrschaft des Bundeskanzleramts, die mit dem Prinzip “Open Social Innovation” an den Erfolg des “#WirVsVirus”-Hackathons anknüpfen möchte. Im Rahmen von Update Deutschland können “Herausforderungen” (= Probleme in Staat und Gesellschaft) eingereicht werden (25.02. bis 17.03.), für die in einem “48h-Sprint” von Teams aus ganz Deutschland Ideen und Lösungen erarbeitet werden (18.03. bis 21.03), die anschließend in einer Umsetzungsphase (15.04. bis 19.08.) praxistauglich gemacht werden.
Die moderne Verwaltung wird schon jetzt mit Open Social Innovation und agiler Arbeit gestaltet. Warum nicht auch die Justiz der Zukunft?
Seán Fobbe
Der Autor ist Rechtswissenschaftler und Legal Data Scientist. Seine Dissertation über ein Thema an der Schnittstelle von Völkerrecht, internationalem Menschenrechtsschutz, Anthropologie und Friedensforschung wird aktuell von der Studienstiftung des deutschen Volkes gefördert. Er ist zudem pro bono als Chief Legal Officer der NGO RASHID International tätig, die auf den Schutz des irakischen Kulturguts spezialisiert ist und bei den Vereinten Nationen special consultative status innehat. Unter @FobbeSean twittert er über Menschenrechte und Data Science.